Week 6 | Session 4: Building a Classification Tree — Gini Index, Splitting & Stopping
Course: Supply Chain Digitization — Module 3: Analytics in SCM
Session Agenda
Section titled “Session Agenda”Recap — Session 3 vs. Session 4
Section titled “Recap — Session 3 vs. Session 4”- Session 3: Showed the OUTPUT of the classification tree — 4 leaf node rules, predictions, how to use on shop floor
- Session 4: Explains HOW the tree was built — the algorithm behind it
- Core algorithm logic: Repeatedly split nodes by choosing the variable and cutoff that maximally reduces impurity → until a stopping criterion is met
Step 1 — Start with Root Node (Node 0)
Section titled “Step 1 — Start with Root Node (Node 0)”- Training data: 700 instances (note: model uses 700, full dataset has 1000 — 700 used for training)
- At root (no feature information): 447 machines failed (Yes) | 253 did not fail (No)
- Baseline probability: 447/700 = 64% chance any randomly picked machine will fail
- Problem with baseline: 64% regardless of age, utilisation, oil contamination etc. — ignores all useful information
- Goal of the tree: Incorporate features to improve accuracy beyond the 64% baseline
- Gini at Node 0: 1 − (0.64² + 0.36²) = 1 − (0.41 + 0.13) = 0.46 (close to maximum of 0.5 → highly impure data → room to improve)
Impurity Measures — Gini Index & Entropy
Section titled “Impurity Measures — Gini Index & Entropy”
Why Impurity? Impurity = randomness in a node. A pure node = all observations belong to one class → perfect prediction. The lower the impurity at each leaf node, the higher the accuracy of classification. Goal at every split: choose the variable + cutoff that reduces impurity the most.
Formulas
Section titled “Formulas”- Gini Index Formula:
Gini(t) = 1 − Σᵢ [ P(class i | node t) ]²- For binary (k=2):
Gini(t) = 1 − (p₁² + p₂²) - Range: 0 (perfectly pure) to 0.5 (50-50 split — maximum impurity)
- For binary (k=2):
- Entropy Formula:
Entropy(t) = − Σᵢ P(class i | node t) × log₂[ P(class i | node t) ]- Range: 0 (perfectly pure) to 1 (50-50 split — maximum impurity)
Gini and Entropy values for key scenarios
Section titled “Gini and Entropy values for key scenarios”| Scenario | Class 1 (%) | Class 2 (%) | Gini Index 1 − Σp² | Entropy -Σp·log₂(p) | Impurity Level |
|---|---|---|---|---|---|
| All in Class 1 | 100% | 0% | 1 − (1² + 0²) = 0 | −(1·log₂1 + 0·log₂0) = 0 | Zero ✓ (Pure) |
| All in Class 2 | 0% | 100% | 1 − (0² + 1²) = 0 | −(0·log₂0 + 1·log₂1) = 0 | Zero ✓ (Pure) |
| 50-50 Split | 50% | 50% | 1 − (0.5² + 0.5²) = 0.5 | −(0.5·log₂0.5 + 0.5·log₂0.5) = 1 | Maximum ✗ |
| Node 0 (Root) | 64% | 36% | 1 − (0.64² + 0.36²) = 0.46 | — | High (near max) |
Key Insight from Impurity Graph
Section titled “Key Insight from Impurity Graph”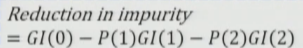
- Shape: Inverted U — symmetric around 0.5
- Both Gini and Entropy start at 0 (all in one class) → rise to maximum at 0.5 (50-50 split) → fall back to 0 (all in other class)
- Implication: When splitting a node, we want to move observations AWAY from 0.5 towards either end (0 or 1) → reduce impurity → improve accuracy
Splitting Logic — How to Choose Variable and Cutoff
Section titled “Splitting Logic — How to Choose Variable and Cutoff”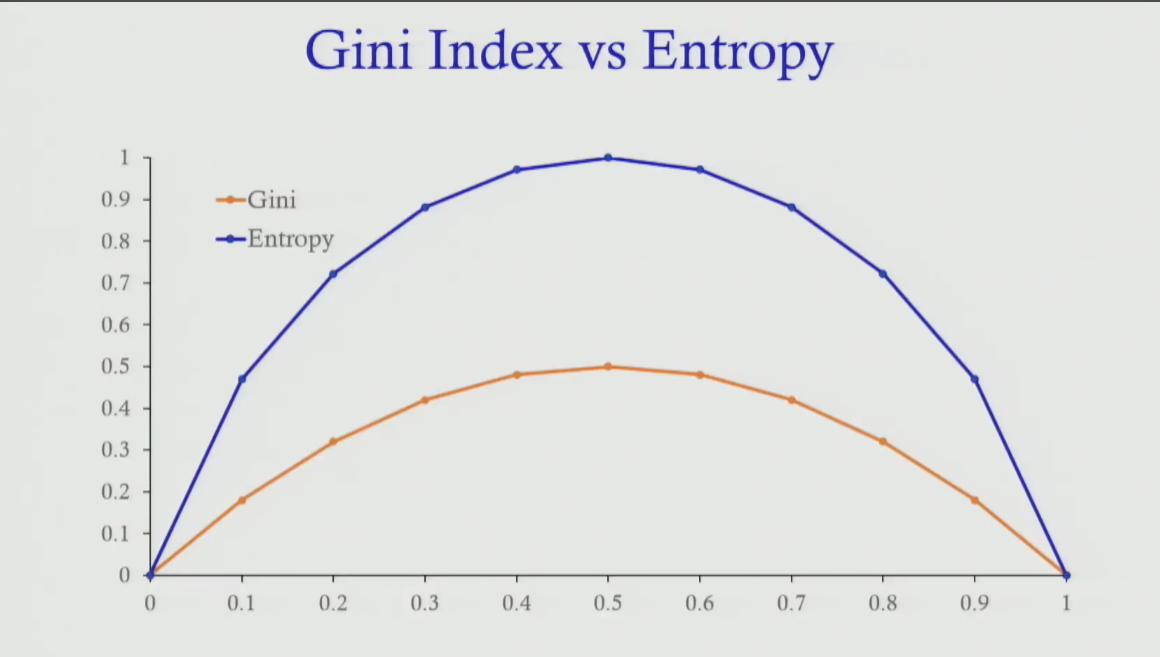
At each node, try ALL variables (age, utilisation, MTBF, oil, etc.) with ALL possible cutoff values. For each (variable, cutoff) pair, calculate weighted reduction in impurity.
- Reduction in Impurity Formula:
ΔImpurity = Gini(parent node) − [ w_left × Gini(left child) + w_right × Gini(right child) ]wherew_left = (obs in left child) / (obs in parent)andw_right = (obs in right child) / (obs in parent) - Choose: The (variable, cutoff) pair that gives the LARGEST ΔImpurity → this is the best split
Node-by-Node Splitting Trace — Full Tree
Section titled “Node-by-Node Splitting Trace — Full Tree”
All nodes — observations, Gini, splitting variable, cutoff, impurity reduction
Section titled “All nodes — observations, Gini, splitting variable, cutoff, impurity reduction”| Node | Obs. Count | Yes% / No% | Gini | Split Variable | Cut-off | Reduction in Impurity | Child Nodes |
|---|---|---|---|---|---|---|---|
| 0 (Root) | 700 total (447 Yes, 253 No) | 64% / 36% | 0.46 | Oil Contamination | 5.5 | 0.052 (Maximum) | → Node 1, Node 2 |
| 1 | 141 total | Oil ≤ 5.5 | 0.44 | Utilisation | 92.05% | 0.38 (Max at Node 1) | → Node 3, Node 4 |
| 2 | 559 total (72% Yes) | Oil > 5.5 | 0.40 | MTBF | 23.95 | 0.11 (Max at Node 2) | → Node 5, Node 6 |
| 3 (Leaf) | 109 obs. | 17% / 83% | 0.28 | STOP | — | — | Predict: NOT FAIL |
| 4 (Leaf) | ~35 obs. | 88% / 12% | 0.21 | STOP | — | — | Predict: FAIL |
| 5 (Leaf) | 493 obs. | 77% / 23% | 0.35 | STOP | — | — | Predict: FAIL |
| 6 (Leaf) | 66 obs. | 29% / 71% | 0.41 | STOP | — | — | Predict: NOT FAIL |
Accuracy Progression — How Each Split Improves Prediction
Section titled “Accuracy Progression — How Each Split Improves Prediction”
| Stage | Information Available | Best Prediction Accuracy | Interpretation |
|---|---|---|---|
| Node 0 (No info) | None — just know the machine exists | 64% (baseline) | 64% chance it will fail based solely on history. |
| After Split 1 (Node 2) | Oil Contamination > 5.5 | 72% (+8%) | Knowing oil is high contamination improves accuracy. |
| After Split 2 (Node 5) | Oil > 5.5 AND MTBF ≤ 23.95 | 77% (+5%) | Adding MTBF info pushes accuracy further to 77%. |
| Node 4 (Best leaf) | Oil ≤ 5.5 AND Utilisation > 92.05% | 88% (+24%) | Highest accuracy leaf — overutilised machines very likely to fail. |
Key takeaway: Each split adds information → accuracy increases. Each additional split adds less accuracy improvement than the previous one (diminishing returns) → reason to stop.
Stopping Criteria & Overfitting
Section titled “Stopping Criteria & Overfitting”Why Stopping is Critical — Overfitting: If no stopping: Tree keeps splitting → eventually each leaf has just 1 observation → 100% accuracy on training data.
- Problem: Model “memorised” training data instead of learning patterns → poor accuracy on new test data (Overfitting).
- Fix: Apply stopping criteria to produce a simpler, more general model.
Three stopping criteria used in classification trees
Section titled “Three stopping criteria used in classification trees”| Stopping Criterion | Definition | How Used in This Example |
|---|---|---|
| Max Tree Depth | Stop splitting once the tree reaches a pre-set maximum depth. | Depth = 2 used. No further splitting beyond that. |
| Min. Observations per Node | Do not split a node if it contains fewer than a minimum number (or %) of training observations. | Node 6 has ~9% and Node 4 has ~5%, triggering stop if min=10%. |
| Min. Reduction in Impurity | Do not split if the gain in purity is below a set threshold (epsilon). | Prevents tiny, meaningless splits. |
4-Step Algorithm — How to Build a Classification Tree
Section titled “4-Step Algorithm — How to Build a Classification Tree”- Start at root: Place all training data in the root node (Node 0). Calculate initial Gini (or entropy).
- Find best split: For each node, try all possible (variable, cutoff) combinations. Select the one that gives maximum reduction in impurity (ΔImpurity).
- Repeat: Apply Step 2 to each new internal node created. Keep splitting until a stopping criterion is met.
- Stop and classify: At each leaf node, assign the majority class as the prediction. Report probability = proportion of that class in the leaf, and support = proportion of training data in that leaf.
Session Summary
Section titled “Session Summary”- Root node baseline: 700 obs | 64% failure rate | Gini = 0.46 — high impurity, needs improvement
- Impurity measures: Gini Index = 1 − Σp² | Entropy = −Σp·log₂(p). Both = 0 for pure nodes, maximum at 50-50 split.
- Splitting criterion: Choose (variable, cutoff) with maximum ΔImpurity
- Accuracy progression: 64% (baseline) → 72% (after oil split) → 77%/88% (after 2nd split)
- Stopping criteria: Max depth | Min observations per node | Min ΔImpurity
- Overfitting: No stopping → 100% training accuracy but poor test accuracy. Stopping = essential for generalisation.
- Next session: Python hands-on — implement this exact model in code, reproduce the same output